
近日,信也科技携手浙江大学合作的论文《Compositional Feature Augmentation for Unbiased Scene Graph Generation》成功获得世界三大顶尖视觉会议之一ICCV 2023收录。该论文首次提出了一种组合特征增强方法(Compositional Feature Augmentation,CFA),可以实现无偏的场景图生成,可用于视觉问答、图片检索、图片生成等大量下游任务,在推荐、搜索、安防与风险反欺诈等领域有着广泛的应用空间。
ICCV即国际计算机视觉大会(IEEE International Conference on Computer Vision),创办于1987年,由美国电气和电子工程师学会(IEEE)主办,被中国计算机学会(CCF)推荐为人工智能领域A类会议,其论文集代表了计算机视觉领域最新的发展方向和水平。ICCV 2023将于2023年10月2日至6日在法国巴黎举办,本届会议共收到投稿8060篇,接收2160篇,接收率约为26.8%。
场景图通常用于描述图片中的物体、物体属性和物体关系,对于理解图片语义信息和控制生成图片逻辑具有重要作用。然而,在不同的图片数据中,物体之间的视觉关系出现的频度差异巨大,具有显著的长尾特征。这给场景图生成的准确性带来了挑战,尤其是带有低频长尾关系的场景图。
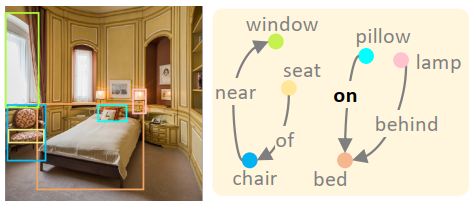
左侧为图片,右图为相对应的场景图
为了克服这一难题,实现无偏的场景图生成,该论文提出的CFA方法,提供了一个高效且具有创新性的组合学习框架,可以丰富长尾关系的特征空间,从而实现无偏的场景图生成。而不仅仅像传统的“再平衡”方法,只是增加已有样本的权重。同时,CFA方法与模型无关,仅在数据层面进行增强,因此具有广泛的适用性。

该图展示了两个进行特征丰富的独立模块的原理,分别基于物体的内在特征和物体之间的上下文关联,提高了场景图生成的准确性。

此次与浙江大学合作的论文,是信也科技在人工智能视觉知识化领域取得的重要突破。信也科技连续5年与浙江大学共建“浙江大学-信也科技人工智能联合研发中心”,持续、多角度布局人工智能前沿科研领域,打造产学研融合通道,实现技术、人才与高校研究之间的有效联动。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
 恒大复牌股价跌近80%!半年
恒大复牌股价跌近80%!半年
 美联储激进加息对A股和港股
美联储激进加息对A股和港股
 铁路暑运累计发送旅客超6亿
铁路暑运累计发送旅客超6亿
 阶段性收紧IPO节奏 专家:
阶段性收紧IPO节奏 专家:
 “AI四小龙”上市之路各不相
“AI四小龙”上市之路各不相
 深圳坪山新能源车产业园一期
深圳坪山新能源车产业园一期

 48小时点击排行
48小时点击排行


